
Що таке SEO і як самостійно розпочати Сео оптимізацію та просування сайту
Зміст
- Seo – що це таке, як впливає на просування
- Чи легко зараз бути Сео-шником
- Під який пошуковик просуватися?
- Біле, сіре та чорне SEO
- Що потрібно знати про роботу пошукових систем
- Індексація сайтів
- Пошук потрібної інформації в індексі
- Релевантність та ранжування результатів
- Облік передачі ваги посилань
- SEO словник – як почати розуміти терміни, які використовують СЕО-шники
- SEO померло? Ні, просто ви не вмієте його готувати
- 5 основних проблем при просуванні комерційного сайту
- Ще кілька поширених проблем із сайтом
- Що ж робити, щоб SEO приносило зиск, а не проблеми?
- Як створити сайт придатний для SEO просування
- 5 способів просування
- Посилальна маса – що це таке і як її правильно сформувати
- Посилання не працюють? А чи це так насправді?
- Як посилання зараз враховуються пошуковими системами?
- Які беклінки купують і навіщо?
- Де зараз можна отримувати зовнішні посилання?
- 100 порад щодо роботи з SEO-посиланнями та способами їх отримання
- Способи оптимізації контенту
- Погані методи просування сайтів на думку Яндекса
- Seo форуми, блоги та соціальні мережі
Доброго дня, шановні читачі блогу DROBRO.com.ua. Сьогодні ми хочемо заявити про створення на нашому ресурсі розділу SEO СЕО, де будемо говорити про те, що таке Seo, показувати сучасні методи Сео оптимізації, яка здатна буквально творити чудеса в просуванні сайту та відповісти на питання, чому не варто в жодному разі нехтувати Search Engine Optimization.
Насправді, хоч ця стартова стаття і адресована в першу чергу вебмайстрам-початківцям, але за своїм досвідом можемо запевнити, що багато вебмайстрів Seo просуванням просто нехтують і навіть не намагаються зрозуміти його суть.
Є дуже побита фраза, яка чомусь стала для багатьох догмою — пишіть статті для людей і успіх не забариться. Так, контент (вміст) безумовно є основним стовпом успішного розвитку сайту, але далеко не єдиним і аж ніяк не достатнім.
Seo – що це таке
Якщо говорити максимально простими словами, то:
SEO – це будь-які дії, спрямовані на виведення вашого сайту або будь-якого іншого вашого ресурсу в топові позиції пошукових систем для залучення відвідувачів.
SEO – це абревіатура від Search Engine Optimization, що можна перекласти як “оптимізація під пошукові ресурси” або “пошукова оптимізація“. Тобто, сюди відносяться будь-які способи покращення позицій вашого сайту у видачах пошукових систем за потрібними вам запитами. Це тягне до збільшення цільового трафіку (потоку відвідувачів) на ваш сайт із пошукових систем.
Тепер дамо більш науково визначення терміну:
Пошукова оптимізація (SEO) — це комплекс заходів щодо внутрішньої та зовнішньої оптимізації для підняття позицій сайту в результатах видачі пошукових систем за певними запитами користувачів, з метою збільшення мережевого трафіку (для інформаційних ресурсів) та потенційних клієнтів (для комерційних ресурсів) та подальшої монетизації ( одержання доходу) цього трафіку.
Цією статтею ми хочемо відкрити вам очі на реальний стан справ (як його бачимо ми) і спробувати переманити вас на «темний бік сили» (адже Seo це не зовсім і не завжди білі методи). Взагалі займатися оптимізацією як внутрішньої, так і зовнішньої, потрібно обов’язково з чітким розуміння того, що саме ви робите і до чого це може привести. Вже страшно? Хочеться все кинути і сказати: “ну його на фіг, нехай все йде як йшло”? Теж вихід, але не найкращий.
Почнемо з кам’яного віку. Інтернет формувався як великий смітник, де поряд з алмазами сусідили величезні маси гумна. Власне, він і досі залишається таким. Головна проблема як користувача, так і вебмайстра, який створив якісний ресурс, це знайти один одного.
Рішення є і його запропонували розробники пошукових систем (читайте про те, як працюють пошукові системи). Вони створили майданчики (щось схоже на біржі), де користувач міг знайти ресурси, що відповідають на поставлене їм питання. Але це рішення має певне обмеження. Реальні шанси на переходи з пошукової видачі мають лише ресурси, які змогли потрапити на її першу сторінку (так званий Топ 10). А це означає, що рано чи пізно за місце у Топ 10 почнеться гризня, і ця гризня почалася.
SEO — це, за великим рахунком, мистецтво попадання на першу сторінку видачі Гугла або Яндекса за пошуковим запитом, що вас цікавить.
Пошуковики досі не можуть запропонувати будь-яке рішення, що дозволяє сайтам, що знаходяться у видачі істотно нижче 10 позиції, отримувати хоча б капельку від числа тих відвідувачів, які вводять у пошуковику питання, що їх цікавить.
Фактично виходить, що життя за топ 10 немає. Тому бійка йде не жартівлива і будь-які методи Сео оптимізації, здатні перетягнути важелі на свій бік, використовуються обов’язково. Взагалі ситуація дуже схожа на те, як це було зображено на великій картинці у статті про ранжування та релевантність сайтів у пошуковій видачі:

Але ж Сео це не тільки технологія, а ще й величезний бізнес.
Знаєте скільки зароблять провідні компанії із цієї галузі? У сумі, думаю, сотні мільйонів доларів, що цілком можна порівняти з доходами хоч не Гугл то Яндекса точно. Як, ви не знали, що пошукові системи це надприбуткові підприємства? Ну, тепер знайте. Заробляють пошукові системи Google і Яндекс на показі контекстної реклами (Дірект та Адвордс).
А хто замовляє у пошукових систем рекламу? Здебільшого власники комерційних ресурсів для залучення до себе відвідувачів. І вся фішка в тому, що обидва ці бізнеси (контекстна реклама та надання послуг Сео просування) є по відношенню один до одного конкурентними.
Тобто, ви повинні розуміти, що Seo реально працює і не використовувати його було б великою помилкою. Ваші потенційні читачі, які не зможуть знайти ваш чудовий сайт через Google чи Яндекс, вам цього не пробачать.
Мало створити хороший проект з унікальним і потрібним контентом, його обов’язково потрібно просунути в Топ 10 хоча б по ряду не дуже частотних запитів, щоб привернути увагу читачів.
Чи легко зараз бути Сео-шником
Зараз працювати в галузі SEO може далеко не кожна людина. Тут потрібен особливий склад характеру, бо існує низка проблем, з якими постійно стикається подібний фахівець:
- Працювати доводиться в умовах постійно (перманентно) алгоритмів роботи пошукових систем, що змінюються. Базові принципи, описані у наведеній за посиланням статті, залишаються постійними, однак змінюються нюанси, які істотно впливають на успіх кампанії з просування сайту. По суті, будь-які раніше виявлені Сеошниками закономірності можуть перестати працювати відразу, і ніхто не може гарантувати працездатність методів, що використовуються зараз. Люди, які люблять стабільність та визначеність, на такій роботі не приживуться.
- Будучи SEO фахівцем ви можете не спати ночами, думати, робити, і протягом півроку буквально «жити» проектом замовника, але в результаті справи у сайту, що просувається, можуть навіть погіршитися. Одночасно хтось може палець об палець не вдарити, а проєкт, що ним просувається, зростатиме у видачі. Звідси випливає досить низька мотивація Сеошників до здійснення трудового подвигу. Багато чого просто не в їхній владі, і успіх часто може визначити щось, що волі сеошника не підвладне.
- Мало того, що результат у SEO за великим рахунком не гарантований, так ще й дійсно грамотних (досвідчених) фахівців у цій галузі досить мало, і вже точно менше, ніж це затребуване ринком. Тому середня кваліфікація середнього сеошника досить низька. По суті, немає інститутів чи академій, які б їх готували. Або, принаймні, у достатній кількості та належної якості. Люди навчаються за курсами, вже не актуальними книгами, статтями та блогами.
- Процесу підвищення освіченості сеошників насамперед перешкоджає те, що предмет їх вивчення не хоче, щоб вони його вивчали та впізнавали. Пошукові системи жодною мірою не зацікавлені у відкритому діалозі із SEO фахівцями, бо, по суті, знаходяться з ними по різні боки барикад. Тому знання доводиться отримувати шляхом спостереження за пошуковими машинами та постановкою експериментів, що не є найпростішим та найефективнішим способом. Між собою сеошники теж не так уже й охоче діляться своїми напрацюваннями.
- Не всі сайти, що пропонуються замовниками, можна просунути засобами SEO в сучасних умовах. Вони могли бути розроблені або дуже давно або без урахування їх можливого просування в пошукових системах.
- Найчастіше власники сайтів самі не знають чого хочуть, і сформульовані ними завдання щодо просування зовсім не відповідають тому, що вони насправді хочуть отримати в результаті роботи спеціаліста Сео. Виникають непорозуміння, але клієнт, як завжди, правий і…
Під який пошуковик просуватися?
Крім всіх описаних вище складнощів, Сеошники змушені при просуванні сайтів намагатися «послужити» принаймні двом господарям – Гугл та його сателіту Яндекс. А якщо брати до уваги і пошук Mail.ru, то трьом, хоча третій з недавніх часів перетворюється на шлак і в недалекому майбутньому кане в небуття.
Гул потужно підріс за останні роки на теренах колишньої колоніальної території, бо раніше перевага в Яндекса була чи не дворазова і ця тенденція після вторгнення рашистів буде тільки рости в геометричній прогресії.
Секрет полягає в тому, що зараз йде тенденція до збільшення частки мобільного трафіку (відвідувачів, що заходять на сайти зі смартфонів і планшетів), а Google тут має величезну перевагу у вигляді власної мобільної платформи Андроїд і встановленим там за замовчуванням їх пошуком. Хід конем, що називається і таких ходів у яскраво вже вираженного монополіста ще з запасом.
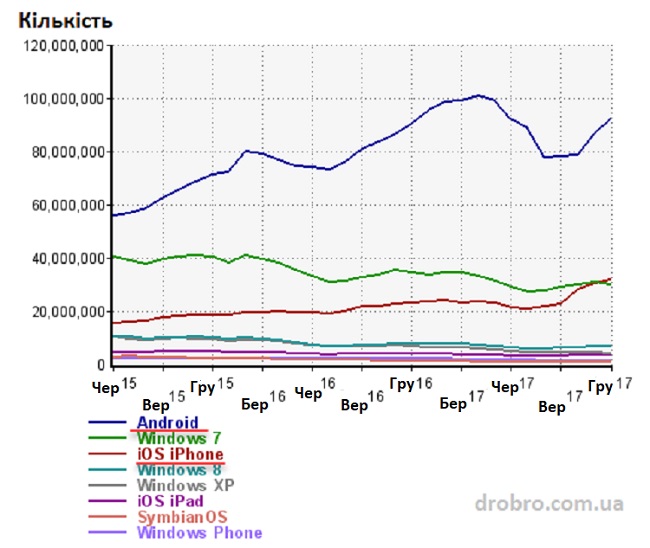
Як видно з даних на графіку, трафік з Андроїда складає більше третини всього трафіку. Ви тільки вдумайтесь? А якщо брати до уваги й інші мобільні платформи, то кількість людей, що заходять у мережу з мобільного, вже перевищила кількість тих, хто заходить з ПК або ноутбука. Далі буде ще більший відхід у мобільність і це знову ж таки додає нових проблем сеошникам і маркетологам, бо суттєво змінюється поведінка користувачів на сайті.
По-любому, від просування в Google (а вже потім в Яндексі, бо і там сидить величезна частина цільової аудиторії з колишнього “совка” за багатьма комерційними тематиками) ніхто просто так відмовитися не може, і практично всі комерційні сайти зараз просуваються під обидві ці пошукові системи.
Ну а якщо сайт буде орієнтований та заточений на “буржунет”, то там вже у Гугла взагалі практично немає гідних конкурентів. На світовому рівні їх навіть не можна порівняти. Людські, фінансові та апаратні ресурси відрізняються на порядок. А це впливає на те, як працюють алгоритми Google, і на те, як швидко він працює загалом.
Крім цього, якщо знову повернутися до колишніх “колоніальних зон” (ua, uz, kz, az, by, tj, am, md, і т.д), то в Яндекса та Гугла суттєво відрізняються аудиторії. Може цілком виявитися так, що вся ваша цільова аудиторія користується лише Гуглом (або Яндексом).
Скажімо так, в Яндексі більше чайників. І це зовсім не погано, бо з них виходять відмінні покупці, але якщо ваш товар або послуга орієнтована на більш просунутих користувачів, то Google може стати для вас основним джерелом трафіку. Якісь глобальні дослідження з цього приводу ви навряд чи знайдете в пабліку, але ми думаю, що почавши розвивати та просувати сайт, ви швидко зрозумієте, яка пошукова система для вас є пріоритетною.
Якщо говорити про пошук Майл.ру, то … краще нічого не говорити. Просто викреслюйте з завдань і не витрачайте час.
Біле, сіре та чорне SEO
Отже, SEO фахівець повинен буде всіма правдами і неправдами змусити згадані вище пошукові системи звернути увагу на сайт який просувається (хоча б у плані його повної індексації) і якимось хитрим і незрозумілим способом змусити їх його полюбити. І це все при тому, що пошукові системи у своїх ліцензіях чітко говорять, що при ранжуванні та визначенні релевантності документів ними враховуватимуться виключно інтереси користувачів пошуку, а аж ніяк не власників ресурсів.
Значить, доведеться «хитрувати» і часто йти на свідоме порушення всіх цих ліцензій. Залежно від ступеня хитрощів та глибини порушень правил пошукових систем SEO просування можна розділити на три групи:
1. Біла SEO оптимізація — всі дії, що вживаються, будуть йти в повній згоді з ліцензіями пошукових систем. Цей шлях складний, трудомісткий, з низькою і відтягнутою за часом віддачею. Але в той же час він найнадійніший, стабільніший і за його використання не буде песимізація, фільтра або бана.
- Прогнозування запитів, за якими користувачі Ґуґла або Яндекса можуть потрапити на ваш сайт. Фактично це складання семантичного ядра за допомогою, наприклад, підбору ключових слів у Вордстаті та створення під них оптимізованих сторінок. Пошукові системи це вітають, бо їм потім буде простіше шукати релевантну запиту інформацію. Але тут, звичайно, не йдеться про переоптимізацію, бо це вже є порушенням ліцензії.
- Оптимізація структури контенту та його внутрішньої перелінковки. Пошуковики знову ж таки не заперечуватимуть, якщо ви таким чином допоможете їхнім роботам швидше знайти і правильно обробити наявний контент. А також показати рівень важливості тих чи інших матеріалів на вашому сайті. Але знову ж таки без фанатизму.
- Природнє нарощування маси посилань. Ключове слово тут «природнє», але про це ми поговоримо трохи згодом.
2. Сіре SEO не зовсім узгоджується з ліцензіями пошукових систем, але саме цей спосіб оптимізації є найбільш популярним і масовим серед Сеошників. Однак це може бути сприйнято як спроби маніпуляції видачею, і на ваш сайт можуть бути накладені санкції (фільтри).
- Купівля та обмін посиланнями у великих масштабах.
- Переоптимізація текстів (спам ключовими словами) для підвищення їхньої релевантності в очах пошукових систем.
3. Чорна оптимізація – відверте порушення ліцензії пошукових систем, за що гарантовано можна отримати накладення санкцій (питання тільки в термінах, протягом яких вас виявлять і прижучать).

Однак, ці методи як і раніше використовуються, і у видачі Гугла і Яндекса можна за деякими запитами спостерігати, наприклад, засилля дорвеїв, а в індексі пошуку так само є величезна кількість ГС (дивіться незрозумілі вам терміни в статті про те, як почати розуміти Сеошників).
Перелічимо приклади чорного SEO без вдавання в конкретику, бо ніколи цим не займалися і не маємо наміру займатися:
- ГС і Дорвеї — створювані вручну або автоматично «погані» сайти, які покликані обманювати пошукові системи (попадати в індекс, щоб з них можна було продавати посилання, або навіть у Топ видачі, щоб на них йшов трафік, який потім перепродуватиметься), але ніякий корисності для відвідувачів не мають.
- Клоакінг
- Прихований (невидимий) текст
- Щось ще про що можна прочитати в ліцензіях (див. ліцензію Гугла для прикладу).
Що потрібно знати про роботу пошукових систем
Однак для того, щоб застосовувати озвучені способи оптимізації, сеошник має насамперед розуміти хоча б загальні принципи роботи пошукових машин. І чим більш ризикованим SEO він збирається займатися, тим глибшими та детальнішими мають бути його пізнання.
Індексація сайтів
Роботу починає пошуковий робот (бот), який є звичайним комп’ютером (сервером) з відповідним ПЗ. Він обходить сторінки з потенційною наявністю якісного та унікального контенту, знаходить веб-сторінку, визначає її вміст (обсяг, якість), і якщо вона йому сподобається, він передає її на наступний рівень, який можна визначити, як пошуковик.
Через апаратні обмеження роботи не снують в інтернеті як заведені, а керуються певними принципами. По-перше, вони ходять на сторінки, на які проставлено багато посилань зі сторінок, які вже є в індексній базі. По-друге, частота повторного відвідування не завжди висока та розраховується індивідуально.

У Яндекса можна виділити два типи роботів:
- Основний робот — індексація основного контенту, що не має характеру новин, коли потрібно буде швидко додати його у видачу. Тут ранжування йде по повному циклу, на відміну від описаного нижче швидкобота.
- Швидкобот — пошуковий робот, який покликаний заповнювати видачу найсвіжішими матеріалами. Він відвідує сайти, де часто з’являється нова інформація (наприклад, блоги з RSS-стрічкою або новинні ресурси). Знайдені ним сторінки ранжуються, спираючись лише деякі внутрішні чинники, і вони миттєво з’являються у видачі із зазначенням дати створення. Але наступного дня позиції з цих запитів можуть змінитися після приходу основного робота індексатора.
Пошук потрібної інформації в індексі
Пошуковик являє собою знову ж таки звичайний сервер (що таке сервер), але з вже іншим програмним забезпеченням. У його завдання входить обхід знайдених ботом сторінок, завантаження їх вмісту і подальша його обробка (створення індексу).
Усі помічені пошуковим роботом сторінки викачуються (у вигляді вихідних Html кодів), з них витягується контент (текст укладений у Html коді, який повинен бачити відвідувач) і проводиться його первинний аналіз та аналіз в цілому. Текст вебсторінки записується в окремий файл (умовно) і туди записуються всі посилання, знайдені на сторінці (вони потім відправляються пошуковому роботу, щоб він туди сходив теж).
З отриманого тексту видаляються всі стоп-слова (союзи, прийменники) і розділові знаки. Отриманий у результаті набір слів розбивають так звані пасажі. По суті це пропозиції, але з деякими припущеннями. Пасажі, як і пропозиції, поєднуються смисловою закінченістю, але оперувати саме пропозиціями, при машинному аналізі тексту, практично неможливо.
Тобто, аналіз ведеться не за фізичними (спочатку наявними в тексті) пропозиціями, а за новоствореними (машинними), які і назвали пасажами. Ну, а ці пасажі вже складаються в індексну базу і кожному пасажу присвоюється свою вагу, що характеризує його значущість всередині цього тексту. Від чого може залежати вага? Наприклад, від того, наскільки пасаж релевантний даному тексту, скільки разів він у ньому повторюється і де всередині тексту він розташований.
В результаті формується база даних (пошуковий індекс), в якій кожна проіндексована вебсторінка представлена набором пасажів з віддаленими шумовими словами (безглуздими, сполучними, паразитними, повтореннями). Саме з цієї бази (індексу) ведеться пошук.
Коли вам потрібно буде увігнати в індекс нові сторінки, що з’явилися на сайті, то найкращим варіантом будуть сервіси по залученню швидкодію (індексатора) пошукових систем. Серед них можу виділити два схожі — IndexGator та GetBot. Коштує ця справа зовсім не дорого, а ефект досить стабільний.
Визначення релевантності та ранжування результатів
На самому верху (до користувачів пошукових систем) знаходиться пошуковий сервіс, який приймає запити від користувачів, і на підставі розрахунку релевантності та застосування факторів ранжування вибирає (із створеного на попередньому етапі пошуковою системою зворотного індексу) потрібні вебсторінки, які потім і будуть показані користувачеві як видача (серпа).
Спрощено це можна уявити так, що відвідувач ПС ставить своє питання і система починає шукати у своїй індексній базі сторінки, що містять пасажі, які максимально відповідають цьому запиту. Отриманий список релевантних сторінок тепер потрібно ранжувати (розставити пріоритети), тобто визначити послідовність розташування цих веб-сторінок у видачі.

Перший принцип, який почав використовуватися дуже давно, називається індексом цитування. У його базовій версії він враховував кількість згадок про цю сторінку (кількість посилань). Про цю систему ми досить докладно писали у статті про те, що таке Тіц та Віц сайту в Яндексі. Недолік такого підходу полягає в тому, що враховується лише загальна кількість посилань, але не їхня якість.
Тому далі був придуманий зважений індекс цитування, який враховує авторитет і якість сайтів, що посилаються. З’являються так звані ваги (статичні), що передаються за посиланнями. В Google цей індекс називається Пейдж Ранком, тулбарне значення якого раніше можна було дізнатися для будь-якої сторінки будь-якого сайту (зараз цю справу прикрили).
Зважений індекс цитування можна описати як коефіцієнт ймовірності попадання відвідувача на цю вебсторінку з будь-якої іншої сторінки мережі Інтернет. Іншими словами, чим більше на цю сторінку посилань і чим більше серед ресурсів, що посилаються, буде авторитетних, тим вірогідніше буде відвідування даної сторінки і тим вище буде її вага. Розраховується він за допомогою формули у кілька ітерацій. Формула ця періодично змінюється та доопрацьовується.
Раніше ми могли спостерігати тулбарне значення ПейджРанку, яке оновлювалося раз на кілька місяців і було побудоване на основі логарифмічної шкали, коли реальна різниця між вагою сторінки з ПР=1 та ПР=7 могла бути тисячократною чи навіть більшою. Подробиці читайте у згаданій вище статті.
Також слід розуміти, що те чи інше значення ПейдРанку для вашої сторінки на її позицію у видачі за тим чи іншим пошуковим запитом прямого впливу не надаватиме. Але в той же час алгоритм, закладений у розрахунку ПР, використовується при ранжируванні сторінок, а отже, його потрібно знати і розуміти, щоб надалі використовувати для своєї користі.
Врахування трансляції ваги посилань при ранжуванні
У схемі ПейджРанка (зваженого індексу цитування) є таке поняття, як вага, що передається за посиланням.
Статична вага, що передається за посиланнями
Передача ваги є не зовсім правильним терміном, бо вага не передається, а транслюється, тобто, донор (читайте статтю про SEO терміни) нічого не втрачає при встановленні посилання, але при цьому акцептор отримує за нею певну статичну вагу. Під терміном статичний слід, потрібно розуміти те, що ця вага не залежить від того, що використовується як анкор посилання.
Скільки ваги може передати та чи інша веб-сторінка в інтернеті можуть знати лише алгоритми пошукових систем. Але достеменно відомо, що ця сама вага буде порівну поділена між усіма сторінками-акцепторами, на які вестимуться посилання з цього донора. Виходячи з цього принципу можна зробити масу висновків щодо зовнішньої та внутрішньої перелінковки свого сайту.
Загальний висновок за принципом трансляції терезів — для того, щоб прокачати якусь свою сторінку, потрібно отримувати посилання на неї, бажано з авторитетних сторінок. А як дізнатися, чи високий авторитет тієї чи іншої сторінки в Інтернеті? Правильно, потрібно подивитися на значення ПейджРанку для неї.

Яндекс теж має аналог ПейджРанку, який розраховується для всіх сторінок (ВІЦ), але дізнатися його значення зараз не представляється можливим. Також у цього пошуковика є в арсеналі ще й тематичний індекс цитування Тіц, при розрахунку якого насамперед враховується тематика ресурсів, що посилаються.
Вимірюється він для всього сайту. Для тематичних посилань (оцінюється тематика за змістом тексту) застосовується підвищуючий коефіцієнт, порівняно з навколотематичними та нетематичними, для яких може застосовуватися серйозна збавка ваги, що передається. Тому для нарощування Тиц важливі посилання не просто з авторитетних ресурсів, а бажано, щоб вони були близькими або збігалися з вашим сайтом. Безпосередньо на ранжування він не впливає, але ті ж принципи використовуються для побудови сайтів у видачі.
Що таке PageRank, у чому він вимірюється і як формується
Насправді він є своєрідним мірилом (критерієм цінності) тієї чи іншої сторінки в інтернеті. Його значення залежить від кількості та якості зворотних посилань, які ведуть з інших сторінок на цей документ. Чим більше посилань — тим вищим буде значення ПР.
Але також дуже важливим є те, яке значення статичної ваги має та сторінка, з якою веде посилання на документ. Справа в тому, що за посиланням передається частина значення PageRank сторінки донора.
Але це ще не все. Справа в тому, що якщо зі сторінки донора проставлено кілька посилань (одна з яких на наш документ), то статична вага, що передається, буде поділена між усіма цими лінками порівну.
Та кількість PR, яку сторінка може передати за посиланням, набагато менша від її власного значення (раніше це було 85 відсотків, а зараз за спостереженнями вже менше 10%). Ця кількість статваги і ділитиметься між документами, на які вона посилається.
Ідеальним буде випадок, якщо зі сторінки, що має Page Rank рівний 10 (максимальне значення), на ваш документ буде проставлено посилання, відкрите для індексації (без атрибуту rel=”nofollow”). І дуже добре буде, якщо вона буде одна єдина.
У цьому випадку вашому документу буде передана гігантська вага, достатня, напевно, щоб ПР вашої сторінки піднявся до 9. Якщо ж з цього ідеального донора буде проставлено ще кілька посилань (включаючи вашу), то вага, що передається за кожною з них, буде вже поділена на загальну кількість та дев’ятку ви вже не отримаєте. Прикро, правда? А так хотілося.
Так, мало не забули розповісти про те, як і в чому вимірюється значення PageRank, а також про те, як заборонити передачу голосу (ваги) за посиланням, що веде зі сторінок вашого проекту. Спочатку про одиниці виміру. Тут є дві шкали і, відповідно, два значення.
Перший варіант виражається його речовим числом і має лінійний характер зміни. Тобто збільшення цього значення буде пропорційно збільшенню кількості статичної ваги, що передається на цей документ за посиланнями з інших ресурсів інтернету. Це число оновлюється практично у реальному часі та постійно враховується під час ранжування.
Другий варіант що представляв PR є похідним від першого. Це значення називалося тулбарним значенням і мало діапазон зміни від 0 до 10 (всього виходить одинадцять можливих варіантів).
Зараз Google не дає можливості подивитися тулбарне значення ПейжРанку.
Тулбарна цифра виходила з дійсного числа за законом, близьким до логарифмічного (сильно нелінійного):
| Дійсне число, яке визначає реальну статвагу | Тулбарне число, яке виходить в результаті |
| від 0,00000001 до 5 | 1 |
| від 6 до 25 | 2 |
| від 25 до 125 | 3 |
| від 126 до 625 | 4 |
| від 626 до 3125 | 5 |
| від 3126 до 15625 | 6 |
| від 15626 до 78125 | 7 |
| від 78126 до 390625 | 8 |
| від 390626 до 1953125 | 9 |
| від 1953126 до безкінечності | 10 |
Тулбарна цифра оновлювалася не часто — раз на кілька місяців. Нульове значення зазвичай мають нові ресурси або проекти, що потрапили під бан Google, а цифру рівну 10 мають лише кілька колосів у всьому інтернеті.
Як ви можете бачити з наведеної вище таблиці – спочатку для нарощування Page Rank не потрібно багато посилань з гарною вагою, але з кожною новою цифрою його подальше збільшення стає все складнішим, а найчастіше нездійсненним завданням.
У середньому добре оптимізовані (і внутрішньо, і зовні) ресурси мають PR головної сторінки рівний 4 або 5, а деякі домагаються навіть шістки, але подальше зростання цього показника доступне тільки дуже серйозним і глобальним проектам.
Отже, межа наших з вами мрій і можливостей — це, швидше за все, 6, та й то навряд. Скажете, що ми песимісти? Та ні, скоріше реалісти. Але якщо ви раптом отримаєте (або вже отримали) Пейдж Ранк рівний 7, то відпишіться, будь ласка, про це в коментарях (і обов’язково поставте посилання на https://www.drobro.com.ua/, щоб і нам стало добре).
Забороняємо передачу статичної ваги через зовнішні посилання
У принципі зробити це зовсім не складно. Google подбав про те, щоб була можливість не віддавати голос на інший ресурс. Для цього достатньо буде додати в тег посилання A атрибут rel=”nofollow” (трохи вище ми вже приводили лінк на статтю, де це все розжовується детально). Наприклад так:
<a href="https://www.drobro.com.ua" >Все про створення сайтів, блогів, форумів, інтернет-магазинів, їх просування в пошукових системах та заробітку на сайті</a>
Після цього статвага з донора не передаватиметься на акцептор (той документ, на який веде лінк). Навіщо може знадобитися забороняти передачу ваги? Тут усе досить просто. Потрібно лише згадати, що PR може передаватися не лише за посиланнями, що ведуть на інші проекти, а й за лінками, які ведуть на внутрішні сторінки вашого ресурсу.
Тепер уявіть таку ситуацію, що у вас в одному документі проставлено десять внутрішніх та десять зовнішніх посилань. Усього виходить двадцять. Статична вага, що передається по кожній з них, дорівнюватиме одній двадцятій від максимально можливого, який здатний віддати даний документ (донор). Отже, акцептори отримають одну двадцяту максимально можливої ваги (пейджранку).
А тепер уявіть, що у всіх зовнішніх посиланнях ви прописали атрибут rel=”nofollow”, тим самим заборонивши передавати по них вагу. В результаті вся вага, яка здатна віддати донор, буде розподілена між десятьма внутрішніми посиланнями. За кожною з них буде передана вага в одну десяту від максимально можливого, що вдвічі більше, ніж у випадку без використання атрибуту rel=”nofollow”.
Таким чином, ви перешкоджаєте витіканню PageRank з вашого проекту, акумулюючи його всередині та підвищуючи свої власні пузомірки. В результаті, ці сторінки вашого ресурсу за інших рівних умов зможуть зайняти більш високе місце в пошуковій видачі Google за рахунок заощадженої статті.
P.S. Є думка, що зараз Google дещо змінив дію атрибуту rel=”nofollow” і ваші внутрішні документи в наведеному прикладі все одно отримають по одній двадцятій вазі, а все інше втече невідомо куди. Думка спірна, але…
Динамічна вага, яка залежить від тексту посилання (анкору)
До цього моменту ми говорили лише про статичну вагу. Однак, при розрахунку трансляції ваги для будь-якого посилання пошукові машини використовують два типи ваг.
Перша — статична, про яку ми вже поговорили і яка розраховується без урахування тексту посилання (її анкору). Друга – динамічна (анкорна), яка розраховується на основі декількох параметрів:
- Тематика донора (звідки проставлене посилання)
- Вміст (тематика) анкору
- Тематичність акцептора (сторінки вашого сайту)
Чим більш релевантні ці три складові, тим більша анкорна вага транслюватиме посилання. Якщо посилання немає анкору (безанкорна), то динамічна вага, що передається по ній, не розраховується зовсім. Статична вага передається завжди, якщо сайт донор не знаходиться під фільтром пошукових систем за продаж беклінків.
Звідси можна зробити дуже важливий висновок — будь-яке посилання, проставлене на ваш сайт, може бути цінним для вас двома своїми вагами. По-перше, ми наздоганяємо статичну вагу своєї вебсторінки, що є добре. Але якщо ще грамотно використовувати анкор, то значимість цього посилання може бути збільшена в кілька разів.
Що потрібно зробити, щоб отримати високу анкорну вагу? Спробуємо розписати за пунктами:
- Донор повинен мати максимально можливий авторитет у пошукових системах. Точніше та сторінка, звідки проставляється беклінк. Раніше можна було про це судити, дивлячись на значення ПейджРанку цієї сторінки – чим менше воно відрізнятиметься від 10, тим краще, але зараз це на жаль у минулому. Доведеться користуватися платними інструментами різних сервісів перевірки сайту.
- Сторінка-донор повинна бути максимально близька за тематикою до сторінки-акцептора (ту що ви просуваєте).
- Анкор посилання теж має бути максимально тематичним сторінці-акцептору (її контенту, тобто тексту).
Про використання в анкорах прямих і розбавлених входжень ключових слів ви можете почитати за наведеним вище посиланням.
Алгоритми прямих та зворотних індексів
Очевидно, що метод простого перебору всіх сторінок, що зберігаються в базі даних, не буде оптимальним. Цей метод називається алгоритмом прямого пошуку і при тому, що цей метод дозволяє, напевно, знайти потрібну інформацію не пропустивши нічого важливого, він абсолютно не підходить для роботи з великими обсягами даних, бо пошук буде займати занадто багато часу.
Тому для ефективної роботи з великими обсягами даних було розроблено алгоритм зворотних (інвертованих) індексів. І, що цікаво, саме він використовується всіма великими пошуковими системами у світі. Тому на ньому ми зупинимося докладніше та розглянемо принципи його роботи.
При використанні алгоритму зворотних індексів відбувається перетворення документів у текстові файли, що містять список всіх слів, що є в них.
Слова в таких списках (індекс-файлах) розташовуються в алфавітному порядку і поряд з кожним з них вказані у вигляді координат місця в веб-сторінці, де це слово зустрічається. Окрім позиції у документі для кожного слова наводяться ще й інші параметри, що визначають його значення.
Якщо ви згадаєте, то в багатьох книгах (в основному технічних або наукових) на останніх сторінках наводиться список слів, що використовуються в цій книзі, із зазначенням номерів сторінок, де вони зустрічаються. Звичайно ж, цей список не включає взагалі всіх слів, що використовуються в книзі, але може служити прикладом побудови індекс-файлу за допомогою інвертованих індексів.
Звертаємо вашу увагу, що пошукові системи шукають інформацію не в інтернеті, а в зворотних індексах оброблених ними веб-сторінок мережі. Хоча і прямі індекси (оригінальний текст) вони також зберігають, так як він згодом знадобиться для складання сніпетів, але про це ми вже говорили на початку цієї публікації.
Алгоритм зворотних індексів використовують усіма системами, так як він дозволяє прискорити процес, але при цьому будуть неминучими втрати інформації за рахунок спотворень, внесених перетворенням документа в індекс-файл. Для зручності збережені файли зворотних індексів зазвичай хитрим способом стискаються.
Математична модель, що використовується для ранжування
Для того, щоб здійснювати пошук за зворотніми індексами, використовується математична модель, що дозволяє спростити процес виявлення потрібних вебсторінок (за введеним запитом) і процес визначення релевантності всіх знайдених документів цього запиту. Чим більше він відповідає даному запиту (чим він більш релевантний), тим вище він повинен стояти в пошуковій видачі.
Значить основне завдання, що виконується математичною моделлю – це пошук сторінок у своїй базі зворотніх індексів відповідних даному запиту та їх подальше сортування в порядку зменшення релевантності даному запиту.
Використання простої логічної моделі, коли документ буде знайденим, якщо в ньому зустрічається фраза, що шукається, нам не підійде, в силу величезної кількості таких вебсторінок, що видаються на розгляд користувачеві.
Пошукова система повинна не лише надати список усіх веб-сторінок, на яких трапляються слова із запиту. Вона має надати цей список у такій формі, коли на самому початку будуть знаходитись найбільш відповідні запиту користувача документи (здійснити сортування за релевантністю). Це завдання не тривіальне і за замовчанням не може бути виконане ідеально.
До речі, неідеальністю будь-якої математичної моделі і користуються оптимізатори, впливаючи тими чи іншими способами на ранжування документів у видачі (на користь сайту, що просувається ними, природно). Матмодель, що використовується всіма пошуковими системами, відноситься до класу векторних. У ній використовується таке поняття, як вага документа стосовно заданого користувачем запиту.
У базовій векторній моделі вага документа за заданим запитом обчислюється виходячи з двох основних параметрів: частоти, з якою в ньому зустрічається дане слово (TF – term frequency) і тим, наскільки рідко це слово зустрічається на всіх інших сторінках колекції (IDF – inverse document frequency).
Під колекцією мається на увазі вся сукупність сторінок, відомих пошуковій системі. Помноживши ці два параметри один на одного, ми отримаємо вагу документа на заданий запит.
Природно, що різні пошукові системи, крім параметрів TF і IDF, використовують безліч різних коефіцієнтів для розрахунку ваги, але суть залишається незмінною: вага сторінки буде тим більше, чим частіше слово з пошукового запиту зустрічається в ній (до певних меж, після яких документ може бути визнаний спамом) і чим рідше зустрічається це слово в інших документах проіндексованих цією системою.
Оцінка якості роботи формули асесорами
Таким чином виходить, що формування видач з тих чи інших запитів здійснюється повністю за формулою без участі людини. Але ніяка формула не буде працювати ідеально, особливо спочатку, тому потрібно здійснювати контроль за роботою математичної моделі.
З цією метою використовуються спеціально навчені люди — асесори, які переглядають видачу (конкретно тієї пошукової системи, що їх найняла) з різних запитів і оцінюють якість роботи поточної формули.
Всі внесені ними зауваження враховуються людьми, які відповідають за налаштування моделі. У її формулу вносяться зміни чи доповнення, у результаті якість роботи пошуковика підвищується. Виходить, що асесори виконують роль такого своєрідного зворотного зв’язку між розробниками алгоритму та його користувачами, який необхідний поліпшення якості.
Основними критеріями щодо оцінки якості роботи формули є:
- Точність видачі пошукової системи – відсоток релевантних документів (які відповідають запиту). Чим менше веб-сторінок (наприклад, дорвеїв), що не стосуються теми запиту, буде присутнім, тим краще
- Повнота пошукової видачі — відсоткове відношення відповідних запиту (релевантних) вебсторінок до загальної кількості релевантних документів, що є у всій колекції. Тобто, виходить так, що у всій базі документів, які відомі пошуку веб-сторінок, що відповідають заданому запиту, буде більше, ніж показано в пошуковій видачі. У цьому випадку можна говорити про неповноту видачі. Можливо, що частина релевантних сторінок потрапила під фільтр і була, наприклад, прийнята за дорвеї або ще якийсь шлак.
- Актуальність видачі – ступінь відповідності реальної веб-сторінки на сайті в інтернеті тому, що про нього написано в результатах пошуку. Наприклад, документ може вже не існувати або бути сильно зміненим, але при цьому у видачі за заданим запитом він буде присутній, незважаючи на його фізичну відсутність за вказаною адресою або на його поточну невідповідність даному запиту. Актуальність видачі залежить від частоти сканування пошуковими роботами документів зі своєї колекції.
SEO словник – як почати розуміти терміни, які використовують СЕО-шники
Люди, які працюють у якійсь певній галузі, використовують у своєму спілкуванні терміни, які допомагають швидко пояснити суть справи, не відволікаючись на деталі.
Через це розмова професіоналів часто здається незрозумілою непідготовленому слухачеві, якому ці деталі, ох як важливі для розуміння. Те саме відбувається і в SEO галузі, де спілкування відбувається з використанням усталеної термінології.

Всі ми, звичайно ж, люди догадливі і за контекстом можемо домислити сенс незрозумілих слів, але все ж таки краще буде разом з ними всіма ознайомитися, щоб уже потім не ламати над цим голову. Власне, у цій статті ми і зібрали ті фрази, якими рясніє мова Сеошників або тих, хто хоче ними здаватися. Якщо щось упустили, або припустилися помилки в інтерпретації, то поправляйте в коментарях.
Серп, Топ, сніпет і тайтл
SERP (видача) — сторінка пошукової системи, яку користувач бачить у відповідь на введений ним запит. Складається він із двох частин — органічна видача (по десять результатів на одній сторінці) та контекстна реклама (кілька блоків зверху, знизу чи збоку від основних результатів пошуку). Саме за місце в Топ 10 органіки і борються SEO фахівці.
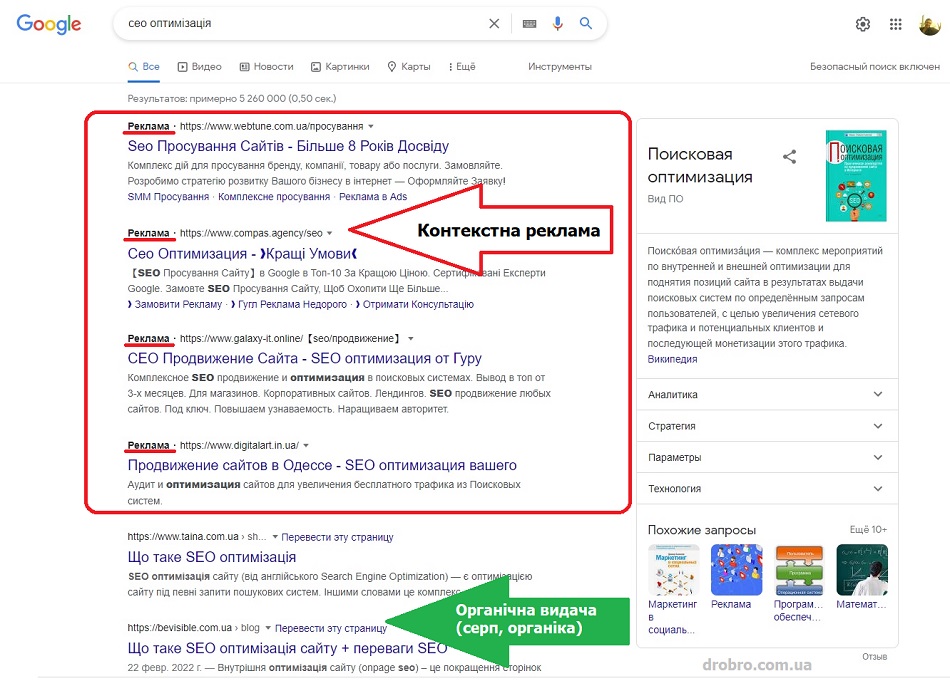
Органічна видача складається з веб-сторінок, які визнані пошуковою системою релевантними запиту. Найчастіше один сайт у видачі представлений лише один раз, але бувають і винятки. Наприклад, у серпі за брендовими запитами.
Саме оголошення для кожної такої веб-сторінки у видачі (серпі) оформлене за певними правилами. В Гуглі та Яндексі їхній зовнішній вигляд трохи відрізняється (наприклад, в Яндексі є фавікони, а в Google можуть бути фото авторів статей).
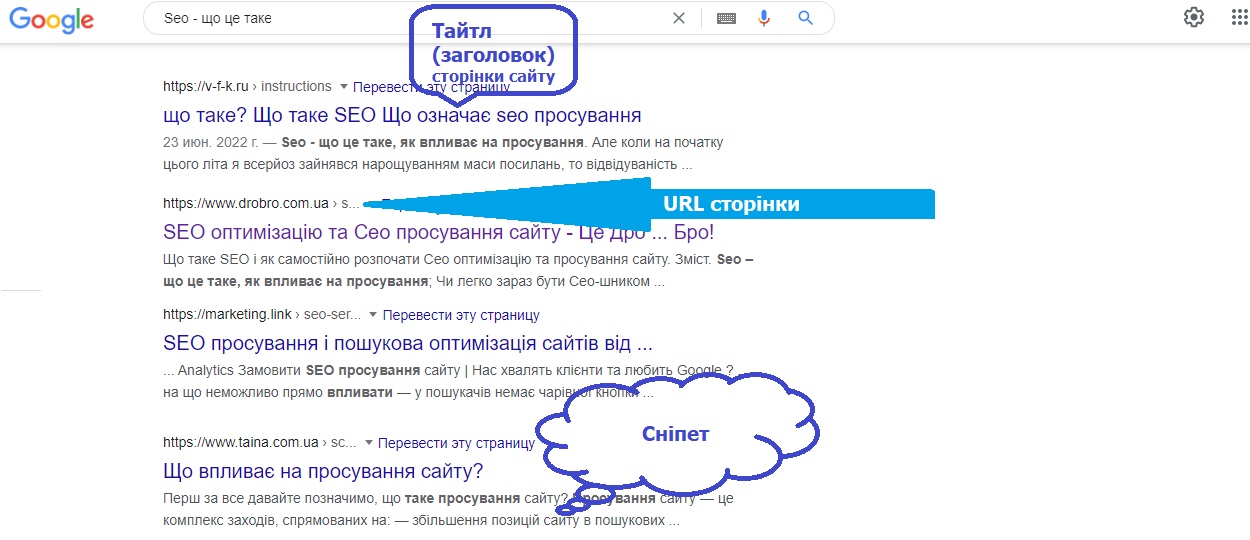
Заголовок цього оголошення зазвичай береться з тайтла сторінки (метатега Title, взятого з вихідного Html коду) представленого сайту, але можуть бути варіанти і використання як проміжні заголовки наявних на цій сторінці.
- Сніппет – розташовується у видачі трохи нижче тайтла та Урла будь-якого оголошення. Представляє фрагмент тексту взятого з вебсторінки що потрапила в серп. Іноді пошукові системи формують його на основі вмісту метатега description (опис сторінки), але також цей текст може бути взятий із самого тіла статті. Так само сніпет може зрідка являти собою напис «Посилання на сторінку містять», коли пошуковий запит не зустрічається на сторінці, а присутній тільки в текстах посилань, що ведуть на неї. Приклад дивіться трохи нижче при поясненні терміну НПС. По суті, це короткий зміст веб-сторінки, який береться з її тексту або вмісту дескрипшен мегатега. По ньому користувач пошукової системи може скласти думку про сторінку без переходу на неї. Сеошники намагаються впливати на сніпети, бо це дозволить залучити більше відвідувачів. Як це зробити? Думаю, що ми ще про це поговоримо докладніше.
- Топ – як правило, під цим мається на увазі перша сторінка видачі пошукової системи. За замовчуванням, на ній відображається десять найбільш релевантних запитів веб-сторінок різних сайтів. Це можна назвати Топ 10. Однак, у Сеошників бувають різні завдання, тому зустрічаються такі речі, як Топ 1, 3, 5, які показують ту стелю, яку вони хочуть досягти в результаті просування (потрапити на перше місце серпа, в трійку або в п’ятірку перших). Відсоток переходів з різних місць першої сторінки видачі настільки відрізняється, що бійка за Топ йде не на життя, а на смерть.
- Тайтл (title) – у Сео термінології під цим розуміють заголовок вебсторінки. Фізично це текст, який в Html коді оточується тегами title і знаходиться в головній частині (між тегами head).
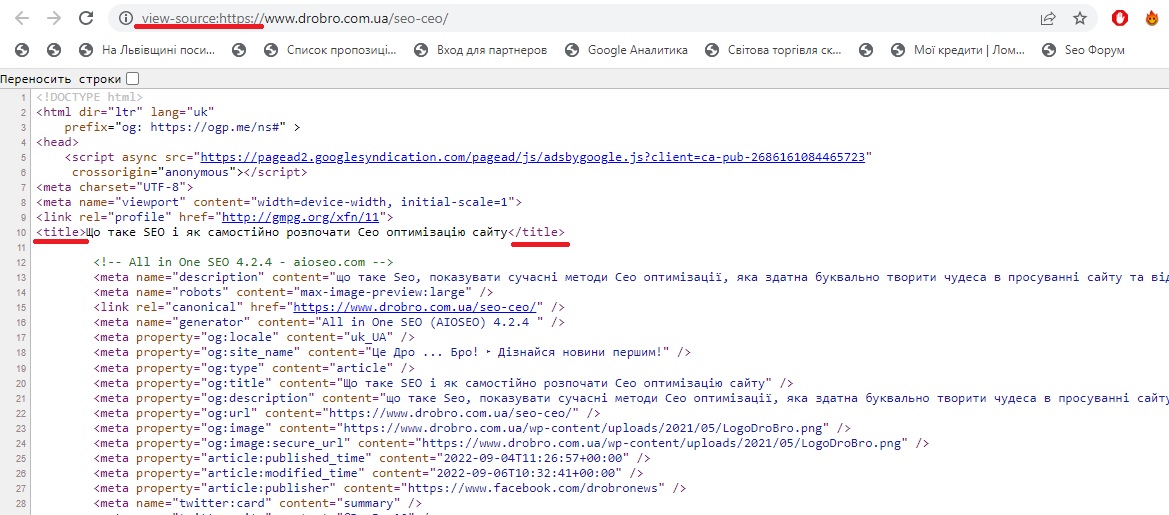
У браузері його також можна переглянути, підвівши курсор миші до однієї з відкритих вкладок.
Включені ключові слова будуть мати більшу вагу для пошукових систем, і його вміст часто використовується як заголовок оголошення в пошуковій видачі (див. скріншот вище).
Індекс, ранжування, фільтри та денс
- Індекс – база даних пошукових систем, де вони зберігають у розібраному на слова вигляді весь вміст інтернету, який їм вдалося проіндексувати. Пошук ведеться не за «живими» текстами на сайтах, а саме за словами цього індексу, що в сотні разів прискорює процес. Для того, щоб почати просування сторінки сайту, треба спочатку дочекатися того, поки вона потрапить до індексу і почне брати участь у ранжуванні за її релевантними ключевими словами запитами (ці терміни описані трохи нижче).
- Ранжування – сортування сайтів у пошуковій видачі. У пошукових систем існує багато факторів (сотні) для ранжування. Зазвичай, серед них виділяють такі групи, як внутрішні (оптимізація сайту, внутрішня перелінковка), зовнішні (статична і динамічна вага проставлених посилань), поведінкові фактори (поведінка користувачів у видачі та на самому сайті), а також соціальні (розшарування сторінок у соцмережах, лайки, коментарі тощо).
- Ключові слова – вони характеризують вміст вебсторінки, щоб пошуковій системі було простіше зрозуміти про що йдеться і яким запитам релевантна дана сторінка. У SEO це архіважливий термін, адже від правильного підбору ключових слів та їх подальшого використання на сторінках сайту, а також в анкорах посилань залежить успіх просування.
- Пошукові запити — те, що користувачі вводять у пошуковий рядок Гугла, Яндекса та інших систем. Де можна побачити статистику пошукових запитів, щоб на їх підставі вибрати собі ключові слова? Правильно, у самих пошукових системах. Вони мають інструменти, які допомагають користувачам контекстної реклами отримати доступ до цієї інформації. Читайте про це у статті за наведеним посиланням.
- Релевантність — відповідність пошукового запиту вмісту веб-сторінки. Усі релевантні запиту документи потрапляють на стадію ранжування, щоб визначити їхню позицію у підсумковій видачі. Бажаєте більше інформації? Читайте статтю про релевантність та ранжування.
- Песимізація – зниження сторінок сайту у видачі за якимись окремими, або навіть за всіма пошуковими запитами (ключовими словами). По суті це штучне заниження релевантності. Зазвичай є наслідком будь-яких виявлених порушень оптимізації чи просуванні. Тому знижується трафік на сайт і сеошник починає шукати і виправляти причини накладання фільтра та інші причини песимізації сайту.
- Фільтри — способи автоматичної боротьби пошукових систем із сайтами, які шляхом накруток намагаються зайняти місце вище, ніж вони на те заслуговують. За допомогою фільтрів пошукові системи намагаються нівелювати дії накруток. Щоб вийти з-під фільтра, потрібно буде усунути причину його накладання (наприклад, переоптимізацію тексту).
- Бан – повне вилучення сторінок сайту з індексної бази пошукової системи. Накладається за дуже грубе порушення ліцензії на використання пошукових систем (наприклад, невидимий текст, клоакінг та інше). Більш детально про фільтри, песимізацію та бан в Яндексі ви можете почитати за наведеним посиланням.
- Апдейт (ап) – у загальному розумінні слова, це оновлення. Стосовно Сео і пошукових систем це може бути апдейт алгоритму ранжування і викликане цим оновлення бази даних (розрахованих на основі цих алгоритмів), яке відбувається не відразу, а від АП до АПа. Це спричиняє зміни серпа (видачі), тобто змінюються позиції сайтів за тими чи іншими запитами. Це і є апдейт видачі, який найчастіше і розуміють під загальним терміном апдейту стосовно SEO. Можете почитати про апдейти, які бувають в Яндексі.
- Денс – процес зміни видачі, який ми спостерігаємо моніторячи позиції свого сайту (вони при цьому можуть стрибати на десятки і навіть на сотні місць вгору або вниз). Справа в тому, що пошукову видачу неможливо оновити миттєво після оновлення або підкрутки алгоритму (програмного забезпечення пошукових систем). Це обмежено технічними можливостями. Крім цього, самі алгоритми мають зворотний зв’язок і можуть підлаштовуватись постійно, тому денс може тривати як днями, так і місяцями, доки все більш-менш устаканиться.
- Кеш (збережена копія) – html версія веб-сторінки з видачі, яка зберігається в базі пошукових систем. Її можна подивитися, наприклад, в Яндексі, скориставшись посиланням «Збережена копія», яка з’явиться при кліку по спойлеру у вигляді маленької стрілочки в кінці URL адреси сторінки:
Іноді це посилання допомагає побачити сторінку на сайті, який зараз тимчасово недоступний (є ще й архів інтернету, але це вже потрібно мудохатись). Кеш потрібен пошуковикам для того, щоб мати можливість формувати сніпети для своєї видачі, бо витягнути його зі зворотного індексу вкрай важко, а лазити постійно на сторінку-джерело дуже накладно.
Афіліат, асесор, протяг і стоп-слова
Афіліат – у видачі за яким-небудь запитом найчастіше представлені різні сайти. Однак у багатьох виникає бажання окупувати весь Топ10. Але як це зробити? Правильно, потрібно створити десять різних сайтів, які будуть належати вам і всі їх просувати у Топ. Це і буде афіліат. Google і Яндекс з цим борються, визначаючи інтернет-магазини та інші комерційні сайти, що належать одному власнику, і залишають в індексі лише одні з них. Цим, до речі, користуються шахраї, викидаючи з індексу таким чином сайти конкурентів.
Трафік – досить загальний термін (що таке трафік), але в SEO зазвичай під цим розуміють трафік на сторінку або на сайт (кількість відвідувачів, які прийшли за певний проміжок часу, наприклад, за добу). Трафік буває пошуковий (з видач Гугла, Яндекса та інших пошукових систем), із закладок (маються на увазі закладки в браузері), соцмережі, покупний і т.п.
Контент – ми вже досить докладно писали про те, що таке контент і наскільки він важливий для просування сайту. Поняття це дещо ширше, ніж просто текст, але під час розмови про Сео мають на увазі саме його текстову складову. Дуже часто йдеться про унікальний контент, про захист контенту від копіювання тощо, бо пошукові системи видаляють дублі зі своїх серверів і вони не беруть участь у пошуку. Існують спеціальні біржі контенту, де за бажання можна замовити або купити вже готову статтю.
Копіпаст – банально скопійований контент. Я не скажу, що, використовуючи копіпаст на своєму сайті, ви гарантовано потрапите під фільтр, але однозначно ні до чого хорошого це не призведе. Проте це одна з основних складових сучасного інтернету.
Копірайтинг – унікальні тексти написані «з нуля». Переважний вид контенту для СДЛ (термін описаний нижче), бо за належного підходу має всі шанси займати високі позиції у видачі.
Рерайт – щось середнє між двома описаними вище термінами. Береться якийсь текст і описується іншими словами із збереженням сенсу. Загалом, це краще, ніж копіпаст, але пошуковими системами «палиться на раз», тому використовуйте рерайт тільки високого класу, а ще краще переходьте на копірайтинг.
Асесор — штатний співробітник Гугла або Яндекса, завданням якого є оцінка пошукової видачі за певними критеріями (і для певних запитів), яка була отримана в результаті роботи алгоритму. Ці оцінки служать зворотним зв’язком, що дозволяє вносити зміни в цей алгоритм, щоб користувачі ПС залишалися ними задоволені, а видача була б релевантною (див. термін трохи нижче) запиту.
Донор (віддає) — у Сео під цим терміном розуміють вебсторінку (або сайт), з якою проставлено посилання на сторінку, що просувається вами. Мається на увазі, що донор передає частину своєї ваги (крові) за цим посиланням (при цьому свою власну вагу не втрачаючи, як це не парадоксально звучить). Якщо ми з цієї статті поставимо посилання на вашу статтю, станемо донором, а ви акцептором.
Акцептор (приймає) – вебсторінка, на яку веде посилання з донора. По суті, вся мережа пронизана донор-акцепторними зв’язками, бо це спочатку було закладено при визначенні, що таке буде інтернет Тімом Бернерсом-Лі (технологія гіпертексту з гіперпосиланнями як сполучні елементи).
Беклінки (зворотні посилання) – посилання на ваш сайт з інших ресурсів (донорів).
Анкор – текст посилання (те, що знаходиться між тегами гіперпосилання, що відкриває і закриває Html). Тут не додати, не зменшити. Посилання можуть бути анкорними та безанкорними. Дуже важливий Сео термін, який враховується при ранжуванні пошуковими системами, і ви можете зустріти в мережі безліч порад про відсоткове співвідношення використання ключових слів в анкорах зворотних посилань (трохи нижче дивіться цей термін). Є такі поняття, як прямі входження ключа в анкорі, розведені чи безанкорні. Читайте докладніше про анкори тут.
Статична вага посилання — пошукові системи в ранжуванні враховують не тільки динамічну вагу посилань (анкори), а й статичну, яка визначається початковою вагою сторінки донора та кількістю веб-сторінок, на які вона посилається. Подробиці читайте у згаданій вище статті.
Жирне посилання — так називають зворотне посилання (беклінк), отримане з дуже трастового ресурсу (з високим Тіц, наприклад). Ще краще, якщо це посилання буде проставлено з головної сторінки. До отримання жирних посилань всі прагнуть, бо це піднімає траст всього ресурсу в цілому і може спричинити зростання трафіку.
ЗНП – знайдено за посиланням (зараз у видачі Яндекса це позначається трохи інакше: «Посилання на сторінку містять»). Справа в тому, що при ранжуванні веб-сторінок враховуються також і анкори (тексти) посилань, які ведуть на цю сторінку. Тому при відповіді на ваш запит пошукова система може пропонувати документи, в яких запит, який ви вводите, не зустрічається, зате є провідні на нього посилання, що містять ці слова.